GLM-5.2 | Open weight LLM | Glm 5.2 vs Opus 4.8 | Open source AI model 2026
Full breakdown: setup, benchmarks, and head-to-head testing

GLM-5.2 (Image edited by Author)
Read here for FREE
In the middle of June 2026, a model called GLM-5.2 took the top spot on Design Arena, a leaderboard where real people vote blind on which AI built the better looking website. The model it pushed down was Claude’s own lineup, Fable 5 included.
So what is this thing, and does it really change anything for people using Claude day to day? Here’s the honest breakdown.
What GLM-5.2 actually is
GLM-5.2 comes from Z.ai, the company formerly known as Zhipu AI, based in Beijing. It’s an open weights model, meaning anyone can download the full thing and run it themselves, no API key required if you have the hardware.
A few specs worth knowing:
- 744 billion total parameters, but it only activates around 40 billion of them for any given task. This is called sparse activation, or mixture of experts. It’s why a model this large doesn’t need a small data center just to answer a question.
- A 1 million token context window, made possible by sparse attention plus a technique Z.ai calls Index Share, which keeps compute costs from exploding even at that length.
- Released under the MIT license, with no regional restrictions. Anyone, anywhere, can use it commercially without asking permission.
I tried it myself (head to head with Opus 4.8)
Benchmarks only tell you so much, so I gave GLM-5.2 a handful of the same tasks I’d normally throw at a new coding model, then ran the same prompts through Claude Opus 4.8 to see how they actually compared side by side. No cherry picking, just the same brief sent to both.
A marketing landing page.
This is the one that surprised me most. I gave both models an identical one line brief and let them run with it. The two pages ended up close enough that I had to look twice to remember which was which. Opus’s version felt slightly more considered in the small details, things like consistent spacing and how numbers were formatted, but GLM’s was not far off, and it got there for a fraction of the cost.
A small finance dashboard.
GLM’s first pass had real bugs. A table of rows stayed hidden until I refreshed the page, and a running total didn’t update after I changed an input. What I didn’t expect was that it caught most of this itself. Because I had it use a browser testing tool as part of the workflow, it opened its own output, noticed the same problems I would have flagged, and fixed them before handing the result back. Opus didn’t have those bugs to begin with, so it’s hard to call this a win, but it changed how I think about GLM’s reliability when it has a way to check its own work.
A 3D racing game built in the browser.
This is where the gap showed up clearly. Opus produced something that actually felt good to drive, smooth car physics, sensible camera, no obvious glitches. GLM’s version technically ran, but the collisions were janky and the car handled like it was on ice. I gave it a second pass to fix the physics and it improved a little, not enough to feel finished.
A WebGL scene with no engine, built from scratch.
Opus finished noticeably faster and the result looked cleaner out of the gate. GLM took close to twice as long to get to a comparable state and needed more back and forth, but it also cost a fraction of what the Opus run did, by a wide enough margin that it’s hard to ignore if you’re running this kind of task at any real volume.
One small thing I noticed across all four tasks: GLM asks good clarifying questions before it writes code, and it tends to mark its suggested default the way Claude does, with something like a “(recommended)” next to one option. I wasn’t expecting an open model to pick up that habit.
Where GLM-5.2 actually makes sense
Putting the benchmarks and my own testing together, a few use cases stand out as genuinely good fits:
- High volume agentic pipelines. If you’re running thousands of agent calls a day, a five times cost difference per token stops being a rounding error and starts being the line item that decides whether a feature is profitable.
- Frontend and landing page work. Its Design Arena win wasn’t a fluke. For marketing sites, dashboards, and brand heavy pages, it consistently lands close to the closed frontier.
- Self-hosting for privacy or compliance. Open weights mean you can run it air gapped, on your own infrastructure, with nothing leaving your network. That matters for regulated industries or anyone who simply doesn’t want their code touching a third party API.
- Developers outside the US. Anthropic’s most capable models, Claude Fable 5 and Mythos 5, had their access suspended for users outside a small group of approved organizations following a US export control directive in mid June 2026. For developers in affected regions, GLM-5.2 is currently the most capable coding model they can legally and practically reach.
- Indie developers and small teams. When you’re testing ten ideas a week instead of shipping one polished product, the last few points of benchmark performance matter less than being able to afford to run the experiment at all.
Where it’s a worse fit: anything that leans on the model reading images, long unattended engineering runs that need to stay coherent for many hours, or work where a small mistake is expensive enough that you want the model with the highest ceiling, not the best price.
How it actually stacks up against the competition
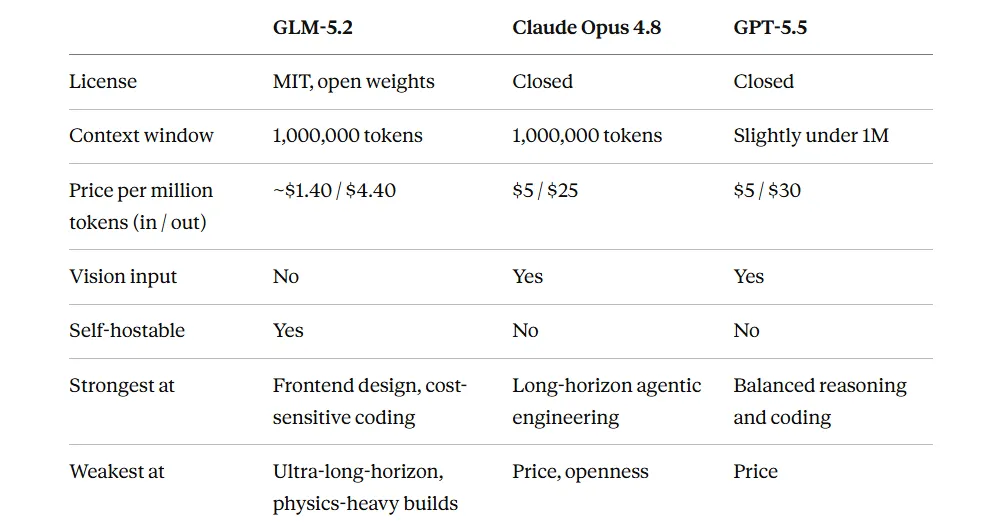
Image Created By Author
The table makes the trade-off obvious. Nobody is paying a five to seven times premium for Opus or GPT-5.5 by accident. That premium buys a longer leash before the model starts making mistakes on the hardest, longest tasks. Whether that’s worth it depends entirely on what you’re building.
4 ways to access it:
- Z.ai’s coding plan. A flat monthly subscription, the simplest path.
- OpenRouter. Pay per token, plug in an API key, done.
- Direct hosting through providers like Fireworks, DeepInfra, or GMI.
- Self-hosting. A 2-bit quantized version shrinks the model from roughly 1.5 terabytes down to around 240GB, while keeping most of its accuracy. You’ll still need 200GB or more of combined GPU and system memory, plus your own inference engine, usually llama.cpp, and some patience downloading the weights.
Plugging it into Claude Code
If you already work inside Claude Code and just want to test GLM-5.2 without switching tools entirely, it’s mostly a settings file edit:
- Open your Claude Code settings file, typically
~/.claude/settings.json. - Set
ANTHROPIC_BASE_URLto Z.ai's API endpoint. - Add your Z.ai API key under
ANTHROPIC_AUTH_TOKEN. - Point
ANTHROPIC_DEFAULT_OPUS_MODEL(and the Sonnet or Haiku slots, if you want) atglm-5.2. - Restart your terminal so the new environment variables take effect.
You can keep separate config files per project, so one folder still talks to Anthropic while another quietly routes through Z.ai. The same setup works with OpenCode and Crush, and if you’d rather skip dealing with Z.ai directly, you can route GLM-5.2 through OpenRouter inside a Claude Code style harness instead.
Only Limitations
- No vision. It’s text in, text out only. You can’t hand it a screenshot of a bug or a photo of a UI you want copied.
- No built in web search. If you want that, you have to wire it up yourself through something like Exa AI.
Neither is a dealbreaker for coding work specifically, but it does narrow what GLM-5.2 is actually good for compared to a model like Claude that handles images natively.
How it scores on paper
- It scored 51 on the Artificial Analysis Intelligence Index. That’s the highest score of any open weight model right now, clearly ahead of MiniMax M3, DeepSeek V4 Pro, and Kimi K2.6, though it still sits behind the top closed models.
- On GDPval, a benchmark built around real world agentic tasks rather than puzzles, it matched and in some readings edged past GPT-5.5.
- Its coding ability lines up closely with Gemini 3.1 Pro, and on several coding benchmarks it actually beats it outright.
- It became the first open model to top Design Arena’s web design leaderboard, ahead of the entire Claude series there.
- On DeepSWE, a benchmark for long running agentic tasks, it falls clearly behind both Opus 4.8 and GPT-5.5, in raw score and in cost per finished task, since it tends to burn through more tokens to get to a working result.
- It’s still behind on some of the harder single shot reasoning tests, like Humanity’s Last Exam without tools.
- Where it’s genuinely strong is real world software engineering and terminal based coding tasks, where it’s usually ahead of other open models like Kimi K2.7 and MiniMax.
So did Claude actually get beat?
Sort of, and only in specific places. GLM-5.2 won one leaderboard that genuinely matters, Design Arena, beating Claude’s full lineup there. It’s matching or nearly matching some of the toughest benchmarks. It’s dramatically cheaper and fully open. But on long, multi-hour agentic engineering work, the kind that requires staying coherent across hours of tool calls and decisions, Opus 4.8 and GPT-5.5 still hold a clear lead, and my own tests backed that up.
There’s also a timing element worth naming directly. GLM-5.2 landed in the same week Anthropic’s most capable models, Fable 5 and Mythos 5, became unavailable to most users outside the US following an export control directive. That’s not a coincidence in how the story got covered. A capable, cheap, open alternative showing up right as the frontier got harder to reach for a lot of the world is exactly the kind of moment that gets a model more attention than its benchmarks alone would earn it.
It’s also worth knowing this isn’t a one off. Z.ai has shipped GLM-5, GLM-5.1, and now GLM-5.2 within months of each other, each one closing the gap a little further. That pace is the real story underneath the headline. A single release beating Claude on one leaderboard is interesting. Three releases in a row each closing the distance is a trend.
The honest takeaway isn’t that Claude lost. It’s that the gap between the best open model and the best closed ones has gotten narrow enough that price, openness, and where you’re allowed to access a model are now doing a lot of the deciding for people, not raw capability alone. That’s a meaningfully different conversation than the one we were having a year ago, and it’s worth paying attention to, even if it isn’t the dramatic upset the headlines make it sound like.
Writers, We’d love to have you!!! Join us and share your stories. Let’s Publish it.